
标签: 领域驱动设计
如何从单体数据湖迁移到分布式数据网格
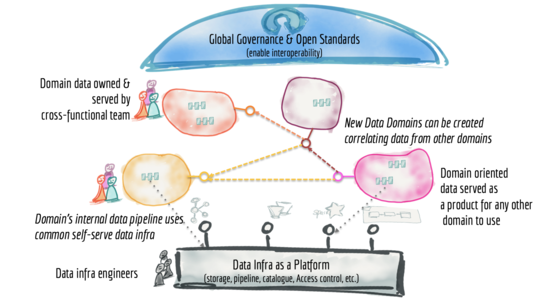
许多企业正在投资于下一代数据湖,希望大规模地实现数据民主化,以提供业务洞察力并最终做出自动化的智能决策。基于数据湖架构的数据平台具有常见的故障模式,这些模式会导致大规模无法兑现承诺。为了解决这些故障模式,我们需要从湖泊或其前身数据仓库的集中式范式转变。我们需要转向一种借鉴现代分布式架构的范式:将领域视为首要关注点,应用平台思维来创建自助服务数据基础设施,并将数据视为产品。
在 Xapo 银行分散架构实践
Xapo 最初是一家比特币服务提供商,后来发展成为一家网上银行。在转型过程中,它需要重新评估其软件资产,并建立架构能力来指导其未来发展。它借鉴了领域驱动设计、团队拓扑和架构建议流程的理念,开发了架构建议论坛。这使得其软件交付团队更加一致,并制定了连贯的技术战略。
限界上下文
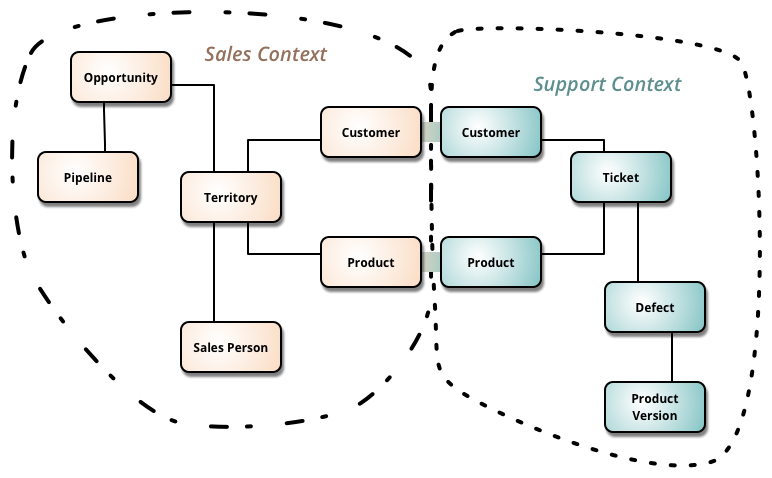
限界上下文是领域驱动设计中的一个核心模式。它是 DDD 战略设计部分的重点,该部分是关于处理大型模型和团队的。DDD 通过将大型模型划分为不同的限界上下文并明确它们之间的相互关系来处理它们。
CQRS
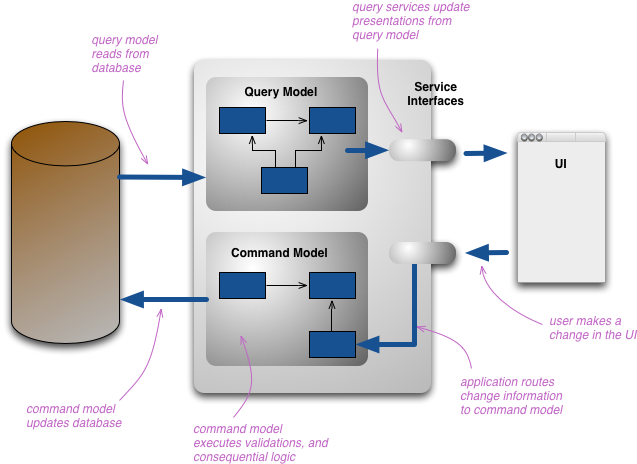
CQRS 代表命令查询职责分离。这是我第一次听到 Greg Young 描述的一种模式。其核心是,您可以使用不同的模型来更新信息,而不是使用用于读取信息的模型。对于某些情况,这种分离可能很有价值,但请注意,对于大多数系统来说,CQRS 会增加风险复杂性。
上下文验证
在我的写作过程中,我一直打算写一些关于验证的材料。这是一个容易引起很多困惑的领域,最好是对一些行之有效的技术进行一些可靠的描述。然而,生活中有很多事情要写,远远超过时间允许的范围。
矛盾的观察
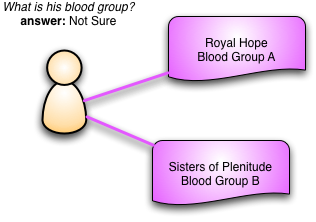
许多计算机系统都是为了存储数据并将其转化为对人类有用的信息而构建的。当我们这样做的时候,自然而然地希望使这些信息保持一致。毕竟,一个对事物有两种看法的计算机系统有什么用呢?
客户忠诚度软件
上周我在卡尔加里办公室,与我们最值得信赖的技术主管之一 John Kordyback 进行了一次愉快的交谈。他参与并深入研究了许多旅行忠诚度软件系统(常旅客/睡眠者等),我们讨论了这些事物的性质,以及如何以更有成效的方式思考它们。
D D D_ 聚合
聚合是领域驱动设计中的一种模式。DDD 聚合是一组可以视为单个单元的领域对象。例如,订单及其订单项,它们将是独立的对象,但将订单(及其订单项)视为单个聚合很有用。
领域驱动设计
领域驱动设计是一种软件开发方法,其核心是围绕对领域的过程和规则有深入了解的领域模型进行编程。这个名字来自 Eric Evans 2003 年出版的一本书,该书通过模式目录描述了这种方法。从那时起,一个实践者社区进一步发展了这些想法,催生了各种其他书籍和培训课程。这种方法特别适用于复杂领域,在这些领域中,需要组织大量通常很混乱的逻辑。
预先读取派生
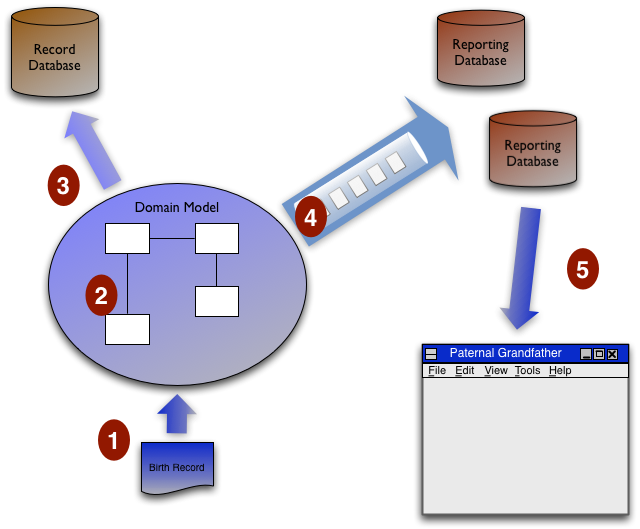
我在QCon 旧金山大会上听过的有趣演讲之一,是由Greg Young做的,内容是关于他在最近一个系统中使用的特定架构。Greg 是领域驱动设计的忠实拥护者,在这种情况下,需要将其与必须处理高交易率并向大量用户提供数据的系统一起使用。我发现他的设计有很多有趣的地方,特别是 er>事件溯源,但在这篇文章中,我只想谈谈一个方面——我称之为预先读取派生。
类型实例同形异义词
“《战争与和平》是一本很棒的书。
“让我看看……可惜这本书的封面这么破旧”
两句话,每句话都用了“书”这个词。我们每天都会浏览这样的组合,却没有注意到“书”这个词在每句话中都有完全不同的含义。
值对象
在编程时,我经常发现将事物表示为复合物很有用。二维坐标由 x 值和 y 值组成。金额由数字和货币组成。日期范围由开始日期和结束日期组成,它们本身可以是年、月和日的复合物。
在这样做的过程中,我遇到了两个复合对象是否相同的问题。如果我有两个点对象都表示笛卡尔坐标 (2,3),那么将它们视为相等是有意义的。由于其属性值(在本例中为其 x 和 y 坐标)而相等的对象称为值对象。